こんにちは!児山です。
今回はタイトルの通りColaboratory上でLightGBMを動かしてみました。
モデルの学習から予測値を出すところまでやったことを備忘録も兼ねて残しておきます。
やることの流れ
-
データの準備
- 予測に用いるデータセットを用意します。
- 特徴量と目的変数を整理します。
- 欠損値の処理やカテゴリカル変数のエンコーディングなどを行います。
-
モデルの設定
- LightGBMのハイパーパラメータを設定します。初学者の場合はデフォルト値を使用することもあります。
-
モデルの実装
- モデルの学習
- 訓練データを使ってモデルを学習させます。
- 予測の実施
- 新しいデータに対してモデルを適用して予測を行います。
- モデルの評価
- 予測結果を実際のターゲット値と比較して、モデルの性能を評価します。
-
検証の可視化
- 予測値と実際の値をプロットして、モデルの予測の妥当性を視覚的に確認します。
データの準備
ライブラリのインポート
今回は以下のライブラリを利用します。
#!pip install lightgbm #Google Colaboratoryでは最初からインストールされているので不要
!pip install japanize-matplotlib
import lightgbm as lgb
import matplotlib.pyplot as plt, japanize_matplotlib
import numpy as np
import pandas as pd
import seaborn as sns
from sklearn.metrics import roc_curve, auc
from sklearn.model_selection import KFold
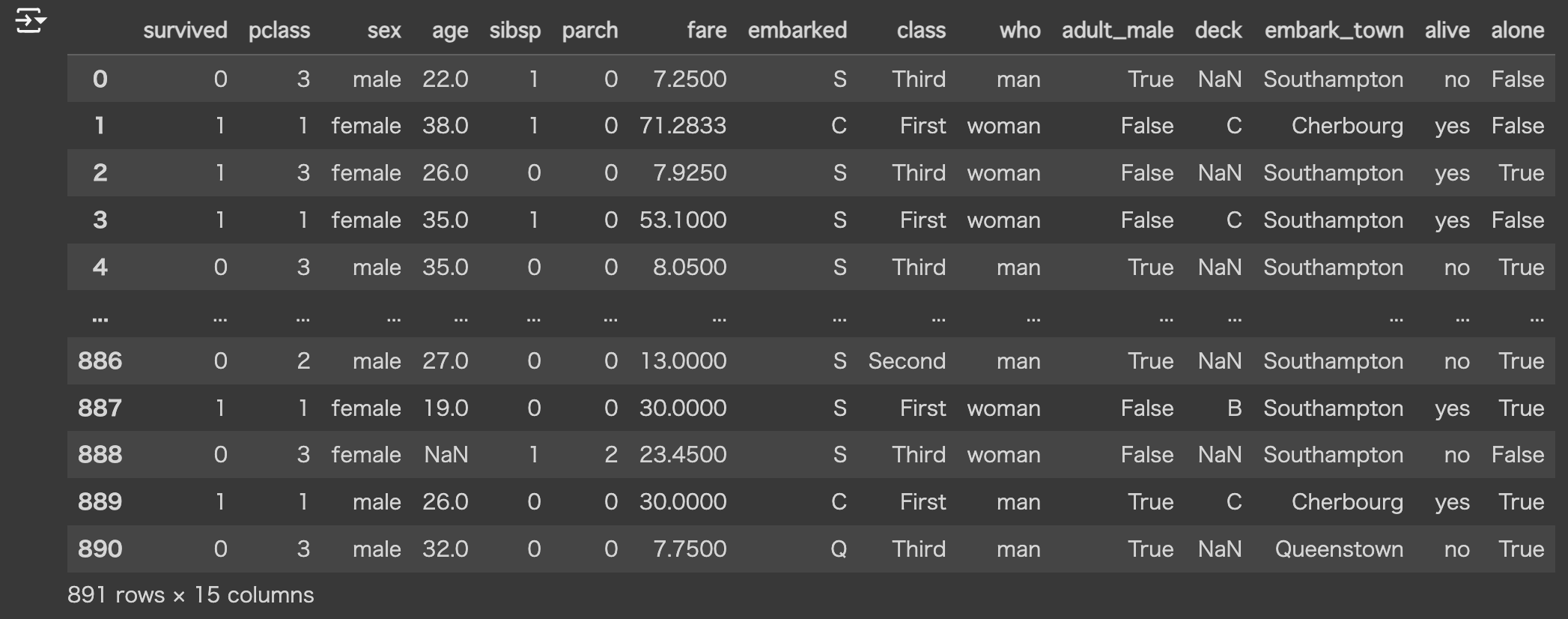
from sklearn.preprocessing import LabelEncoder使用するデータセット
seabornライブラリからダウンロードできるtitanicのデータを利用します。
import seaborn as sns
df = sns.load_dataset("titanic")
df▼ 出力結果
目的変数と説明変数
以下の通りとします。
- 目的変数:生存フラグ(survived)
- 説明変数:生存フラグ以外の変数全て
- survivedは目的変数なので除きます
- aliveカラムはsurvivedと同等の意味合いを持つ変数なので、説明変数から除きます
# 目的変数 y = df['survived']
説明変数
X = df.loc[:,(df.columns!='survived')&(df.columns!='alive')]
本来は特徴量として使用する変数を精査しますが、
今回はLightGBMの実装を一通り行うことを目的にしているため、一旦上記の説明変数全てを特徴量として使用します。
### 欠損値の取り扱いとカテゴリカル変数の明示
- LightGBMでは数値型とカテゴリ型で欠損値の扱い方が変わります。
- カテゴリカル変数に対する欠損値の処理はLightGBM側で自動で実行してくれるのですが、そのために前処理が必要になります。
今回は以下のような前処理を行います。
1.特徴量のうち、カテゴリカル変数であるカラムを洗い出します。
```python
cat_features = X.select_dtypes(["object", "category"]).columns.to_list()</code></pre>
<p>2.カテゴリ変数に対してLabelEncodingを行います。</p>
<ul>
<li>カテゴリ変数は、整数(int型)でエンコードすることが公式に推奨されています。
<pre><code class="language-python">
# LabelEncoderをインスタンス化
le = LabelEncoder()</code></pre></li>
</ul>
<h1>カテゴリカル変数に対してLabel Encodingを適用</h1>
<p>for col in cat_features:
X[col] = le.fit_transform(X[col])</p>
<pre><code>3.後ほどモデルにfitさせる際にcat_featuresを引数として指定します(ここの実装は後述します)
### 学習データとテストデータの分割
後ほど機械学習モデルを作成した後に、学習に使ったデータセット以外の未知のデータに対する性能や予測能力(これを汎化性能といいます)を検証するためにk-fold交差検証を行います。
予め学習を行うための学習データと未知のデータに適用したときのモデルを評価するためのテストデータに分割します。
```python
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size = 0.3, random_state = 0)モデルの設定
-
今回はほぼデフォルトの状態のパラメータ指定で実装します。以下のみ明示します。
-
objective(目的関数): binary
-
今回やりたいことは二値分類(生存した/生存しなかった)なので、モデルの設定も二値分類(binary)を指定します
- もしやりたいことが回帰タスクの場合はregression、多クラス分類タスクの場合はmulticlassを指定します。
-
モデルの実装
まずは実装したコードを一旦記載します。コードが長いので、実装内容の詳細と実行結果はこの後解説します。
#モデルの設定
param = {"objective": "binary"}
best_iterations = {}
models = {}
scores = []
# k-Fold交差検証を実行
kf = KFold(n_splits = 3, shuffle=True, random_state=0)
for curr_fold_num, (train_idx, test_idx) in enumerate(kf.split(X, y)):
# 学習データとテストデータを取得
X_train, X_test = X.iloc[train_idx], X.iloc[test_idx]
y_train, y_test = y.iloc[train_idx], y.iloc[test_idx]
train_data = lgb.Dataset(X_train, label=y_train)
valid_data = lgb.Dataset(X_test, label=y_test)
# 評価指標の格納先
evals = {}
# モデルを学習
bst = lgb.train(param,
train_data,
valid_sets=[valid_data],
callbacks=[lgb.record_evaluation(evals), lgb.early_stopping(20)],
categorical_feature=cat_features,
)
# テストデータで予測
oof_preds = bst.predict(X_test, num_iteration = bst.best_iteration)
# AUCの算出
fpr, tpr, threshold = roc_curve(y_test, oof_preds)
scores.append(auc(fpr, tpr))
# 最良の予測器が得られたイテレーション数
best_iterations[curr_fold_num] = bst.best_iteration
# 損失関数をプロット
lgb.plot_metric(evals)
# 特徴量の重要度をプロット
lgb.plot_importance(bst)
# モデルを格納
models[curr_fold_num] = bstモデルの学習
以下の箇所で学習データとテストデータの取得?学習までを行っています。
# 学習データとテストデータを取得
X_train, X_test = X.iloc[train_idx], X.iloc[test_idx]
y_train, y_test = y.iloc[train_idx], y.iloc[test_idx]
train_data = lgb.Dataset(X_train, label=y_train)
valid_data = lgb.Dataset(X_test, label=y_test)
# 評価指標の格納先
evals = {}
# モデルを学習
bst = lgb.train(param,
train_data,
valid_sets=[valid_data],
callbacks=[lgb.record_evaluation(evals), lgb.early_stopping(20)],
categorical_feature = cat_features,
)- lgb.trainの引数について
- 今回は以下の設定を行っています
- 二値分類であること(モデルの設定で言及したものです)
- 学習データと検証データに用いるデータの指定
- 各イテレーション時に実行したい関数関数の指定(後述します)
- カテゴリカル変数の設定(欠損値の取り扱いとカテゴリカル変数の明示で作成したリストをここで指定します)
- callbacks内に各イテレーション時に実行したい関数を格納しています。
- record_evaluation:引数のevalsにテストデータでの評価した際の評価指標の値を記録します。
- evalsは後でモデルの検証時に利用します。
- early_stopping:最低限イテレーションを回す回数を指定します。
- LightGBMでは学習時に複数回決定木モデルを作成する(デフォルトだと100回)のですが、early_stoppingを指定しておくとテストデータで一定回数連続でスコアが改善しなかった場合に、指定した学習回数に達しなくとも学習を打ち切ります。
- 過学習の防止・処理にかかる時間の削減というメリットと学習が不十分で誤判定につながるおそれがあるというデメリットのトレードオフを最適化するための処理です。
予測の実施
- こちらの部分でテストデータを使って予測を行っています。
- best_iterationで学習時に最も予測精度が高かった予測器を指定しています。
# テストデータで予測 oof_preds = bst.predict(X_test, num_iteration = bst.best_iteration) - 予測に使ったモデルはmodelに格納しておき、後から呼び出せるようにしています。
# モデルを格納 models[curr_fold_num] = bstモデルの評価
- best_iterationで学習時に最も予測精度が高かった予測器を指定しています。
AUCを使ったモデルの評価
-
AUCの算出方法についてはこちらの記事で触れているので、関心がある方はこちらも合わせてお読みください。
-
AUCの読み取り方だけ簡単にまとめておきます。
- 0~1までの値を取ります
- 0.5だと精度はランダムに予測しているのと同等です。
- 1に近づくにつれ精度が高くなります。
- 0に近づく場合も精度が高くなるのですが、陽性・陰性を逆に判定している状態です
先ほどの実装の以下の部分で
- roc_curveメソッドを使って真陽性率、偽陽性率、陽性/陰性を判断するための閾値の取得
- 真陽性率、偽陽性率をauc()の引数にとりAUCの面積の算出
を行っています。
# AUCの算出
fpr, tpr, threshold = roc_curve(y_test, oof_preds)
scores.append(auc(fpr, tpr))scoresに格納している理由は後述します。
k-fold交差検証
- 機械学習を行うとき、1つの学習データに適応しすぎると過学習が起こり、未知のデータに対する精度が下がる恐れがあります。
- 未知のデータに対する性能(汎化性能と言います)を評価したり、過学習のリスクを検知できるようにk-fold交差検証を行います。
下の図のようにデータをいくつかに分解し、分割したデータすべてが1回ずつテストデータになるように学習を行なった後に精度の平均をとることでモデル精度を評価します。
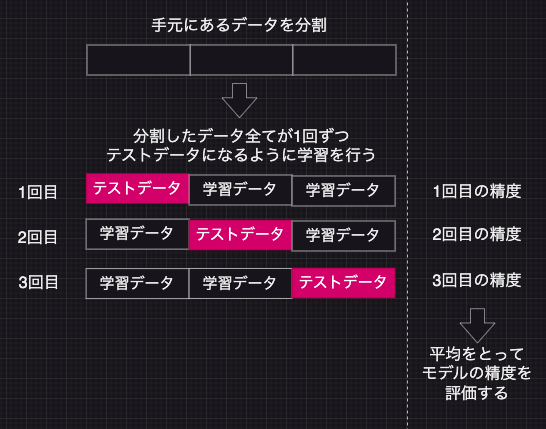
今回の実装上ではデータを3つに分割してループを回しています。
# k-Fold交差検証を実行
kf = KFold(n_splits = 3, shuffle=True, random_state=0)
for curr_fold_num, (train_idx, test_idx) in enumerate(kf.split(X, y)):
#ループの配下でモデルの学習・予測、モデル性能の評価を行うモデルの精度は先述した通りAUCを使って評価しています。
ループを1回回すごとにAUCの面積をscoresというリストに格納しているため、
以下のようにscoresの平均を出すことでAUCの平均値を求めることができます。
print(f"""
Average AUC: {np.mean(scores)}
""")実行してみるとAUCの平均は0.867という結果になりました。
![]()
まとめ
今回はLightGBMの機械学習モデルを実装してみました。
注意が必要なのは今回作成したモデルがあくまでこのモデルに用いた特徴量を用意できれば
AUC0.867の精度で生存するか生存しないかの予測ができる、という点です。
つまり、タイタニック号と同時代・同規模の客船であればそれなりの精度で予測ができるかもしれませんが現代の一般的な客船や貨物船にも適用できるような外的妥当性はありません。
もし現代の貨客船でも通用するような特徴量を使ってモデルを構築する場合は
例えば、現代の客船のデータを元にモデルを構築する、運賃を現代価格に置き換えるなど様々な条件をそろえた上でモデルを作成することが重要になります。
今度は別のデータを使って実装してみたいですね。
以上お読みいただきありがとうございました。
以降はおまけになります。
おまけ:検証の可視化
その1:損失関数の確認
- モデルの予測精度が収束していなかったり、過学習を起こしていないかを確認するために損失関数を確認する方法を記載します。
先ほどモデルの学習時にevalsへ格納した評価指標をプロットします。
今回は2値分類を指定しているので、評価指標にはbinary_loss(ざっくりいうとモデルの予測と実際のテストデータの結果のずれを対数の形でとったもの)がデフォルトで入ってます。
# 損失関数をプロット
lgb.plot_metric(evals)▼実行結果
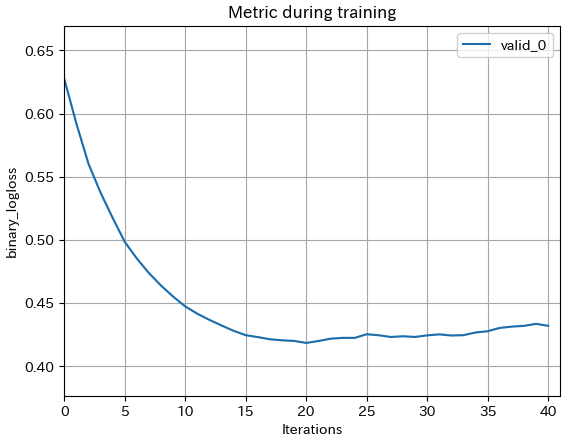
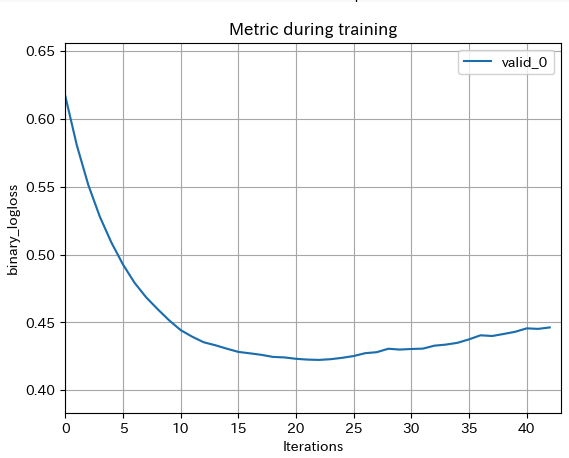
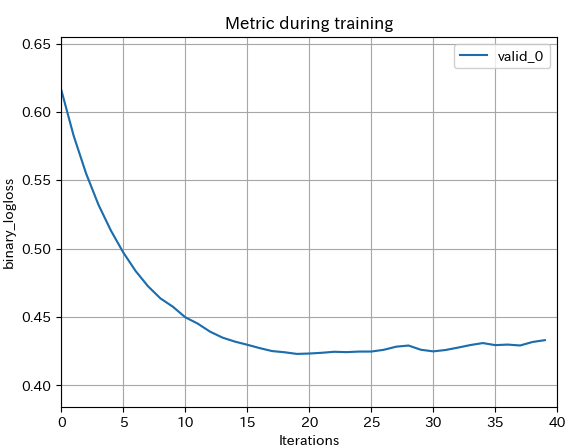
今回はk-fold交差検証により3回に分けて学習しているので3つグラフが表示されます。
学習時の訓練回数が20回を超えたあたりから徐々に精度が落ちており、過学習を起こしている可能性があります。
サンプルを増やす、学習回数を調整する、学習時に作成する決定木の深さを調整するなどパラメータ調整の余地がありそうです。
その2:特徴量の重要度の可視化
- モデルがどの特徴量を重視しているのか、予測の根拠は何かなどの解釈性を高めるために特徴量の重要度を確認する方法を記載します。
# 特徴量の重要度をプロット lgb.plot_importance(bst)▼実行結果
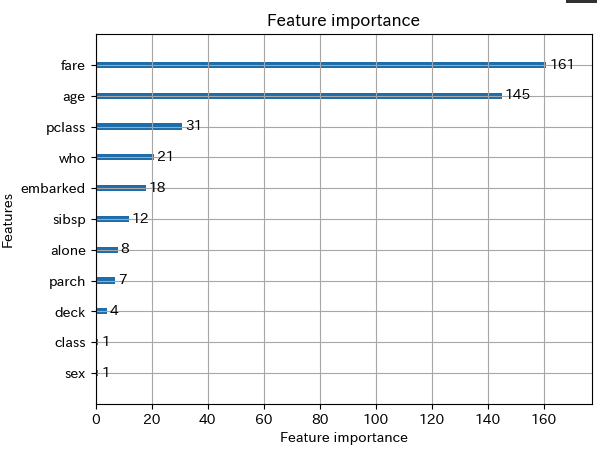
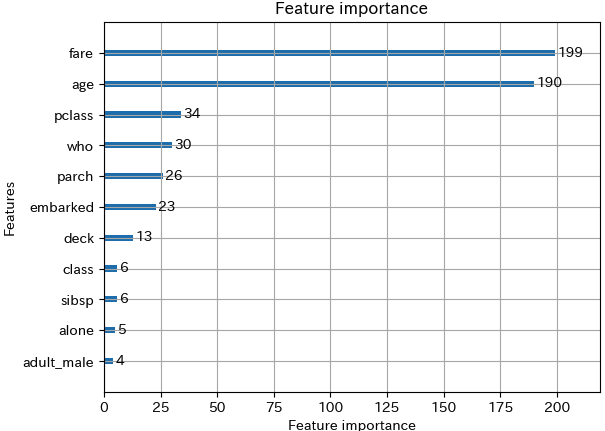
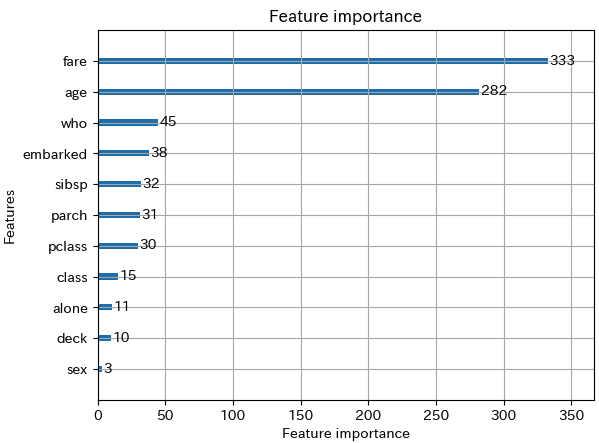
このモデルではfare(運賃)とage(年齢)の影響を重視しているようです。
モデルが何の特徴量を重視したかを可視化することの意義
- データの解釈性を高めるために用いる
- 例えば「年齢が高いほど生存率が高い」「 裕福な層ほど生存率が高い」という情報を重視していることから 「実は裕福な層ほど生存率が高く、裕福な層ほど平均年齢が高く運賃が高かったという疑似相関があったのではという仮説が立てられる」、などモデルの予測の根拠や解釈を説明しやすくなります。
- モデルの精度向上のために用いる
- 例えば、「運賃は旅客クラス(pclass)や乗降地(Embarked)とも関連しそうなので、それらを組み合わせた新たな特徴量を用意する」など精度が高めるためのアイデアを練るヒントになります。
最後までお読みいただきありがとうございました。