2019/9 Webアーキテクチャ基礎(後半)

前回に引き続き、Web開発する上で基本的なアーキテクチャ概念を紹介します。※本記事はWeb Architecture 101を意訳したものです。Thank you Jonathan Fulton.
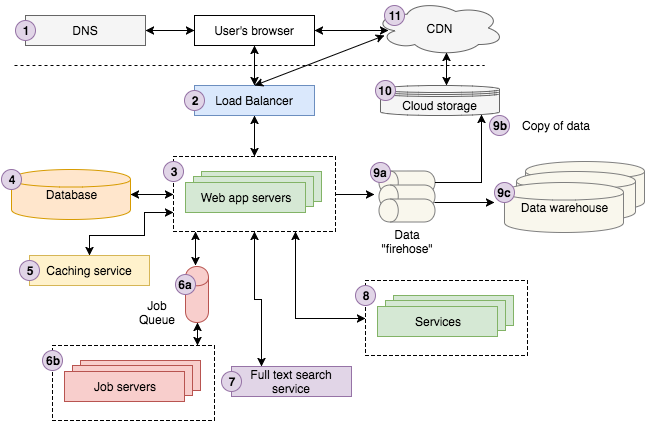
6. ジョブキュー&サーバ
ほとんどのWebアプリはユーザのリクエストへの応答には直接関係しない裏側で非同期に処理を行ことがあります。例えばGoogleは検索結果を返すために、インターネット全体をクロールしてインデックスを作成します。検索するたびにクロールするわけではありません。代わりにWebを非同期でクロールし検索インデックスを途中で更新します。非同期作業を行うものには様々なアーキテクチャがありますが、最も一般的なのは「ジョブキュー」アーキテクチャと呼ばれるものです。これは2つのコンポーネントで構成されます。「ジョブ」をためるキューと、キュー内のジョブを実行する1つ以上のジョブサーバ(「ワーカー」と呼ばれることが多い)です。
ジョブキューには非同期実行が必要なジョブ一覧が保存されます。一番単純なものは先入れ先出し(FIFO)キューですが、ほとんどのアプリは最終的に何らかの優先順位キューシステムが必要になります。アプリ側は何らかの定期的なスケジュールかユーザアクションで必要になるたびに適切なジョブをキューに追加するだけです。
例えばStoryblocksではジョブキューを活用して、マーケットプレイスを補助するために必要なバックグラウンドタスクを実現しています。ビデオや写真のエンコード、メタデータのタグ付のためのCSV処理、ユーザ統計の集計、パスワードリセットメールの送信などのジョブを実行します。最初は単純なFIFOキューから始めましたが、優先度キューにアップグレードし、パスワードリセットメールの送信など時間をかけたくない処理をできるだけ早く完了できるようにしました。
ジョブサーバはジョブを処理します。ジョブキューをポーリングして、実行するジョブがあるか判断し、ある場合はキューからジョブをポップして処理します。言語とフレームワークの選択はWebサーバと同じぐらい多いので、この記事で割愛します。
7. 全文検索
ほとんどのWebアプリはユーザにテキスト検索(「クエリ」と呼ばれることが多い)を提供し、アプリが最も「関連性の高い」結果を返すような検索機能を提供しています。検索機能を強化する技術は一般的に「全文検索」と呼ばれ、転置インデックスを活用してクエリキーワードを含む文章を素早く検索します。

特定のキーワードからタイトルに含まれるキーワードを素早く検索するために、3つのタイトルを転置インデックスに変換する例です。
一部のDBは直接全文検索を実行することはできますが(例えばMySQLは全文検索をサポートしています)、転置インデックスを計算し保存しクエリインターフェースを提供する別の「検索サービス」を使うのが一般的です。今、最も人気のある全文検索プラットフォームはElasticsearchですが、SphinixやApache Solrなど他の選択肢もあります。
8. サービス
Webアプリが一定の規模に達すると、別のアプリとして切り分けられた「サービス」となる場合があります。外部にさらされませんが、アプリや他のサービスは外部とやり取りします。例えばStoryblocksはいくつかの運用サービスと計画サービスがあります。
- アカウトサービスはすべての自サイトのユーザデータを保存するため、わかりやすい連携機能を提供し、より統一されたUXを作ることができます。
- コンテンツサービスはすべての動画、音声、画像コンテンツのメタデータを保存します。また、コンテンツをダウンロードしたりダウンロード履歴を表示するためのI/Fも提供します。
- ペイメントサービスは顧客にクレジットカード請求するためのI/Fを提供します。
- HTML → PDFサービスはHTMLを受け取り対応するPDFドキュメントを返すシンプルなI/Fを提供します。
9. データ
今日、企業はデータをいかに上手く活用しているかによって生き死にが決まります。最近のほぼすべてのアプリは一定の規模に達すると、データパイプラインを活用してデータを確実に収集、保存、分析できるようにします。典型的なパイプラインには3つの主要な段階があります。
-
アプリはデータ(通常はユーザ操作に関するイベント)をFirehoseに送信します。Firehoseはデータを取り込み、処理するストリーミングI/Fを提供します。多くの場合、生データは変換・拡張され別のFirehoseに渡されます。AWS KinesisとKafkaはこの目的のための一般的なテクノロジーです。
-
生データと最終的な変換・拡張データはクラウドストレージに保存されます。AWS KinesisはFirehoseと呼ばれる機能があり生データをクラウドストレージ(S3)に非常に簡単に設定できます。
-
多くの場合、変換・拡張されたデータは分析のためにデータウェアハウスに読み込まれます。大企業の多くはOracleまたは独自ウェアハウス技術を使用しますが、我々はAWS Redshiftを使用しています。データセットが大きい場合、分析にはHadoopのようなNoSQL MapReduce技術が必要になる場合があります。
アーキテクチャ図に示されていない別のステップ:アプリとサービスの運用データベースから、データウェアハウスにデータを読み込みます。例えばStoryblocksでは、VideoBlocks、AudioBlocks、StoryBlocks、アカウントサービス、提供者ポータルデータベースを毎晩Redshiftに読み込んでいます。ユーザ操作データやコアビジネスデータを同じところに置くことで、アナリストに全体的なデータセットを提供します。
10. クラウドストレージ
AWSによると「クラウドストレージは、インターネット経由でターを保存・アクセス・共有するためのシンプルでスケーラブルな方法」です。HTTP経由のRESTful APIを介して操作できる利点があり、これを利用すればローカルに保存するもののいくつかは、クラウドストレージに保存およびアクセスできます。AWS S3は今日最も人気のあるクラウドストレージであり、ビデオ、写真、音声、CSS、Javascript、ユーザ操作データなどを保存するためにStoryblocksでは広く活用しています。
11. CDN
CDNは「Content Delivery Network」の略で、この技術は静的なHTML、CSS、Javascript、画像などのアセットを、単一のオリジンサーバから配信するよりも遥かに高速に配信することができます。世界中にあるたくさんの「エッジ」サーバからコンテンツを配信することで、ユーザは元のオリジンサーバではなく「エッジ」サーバからアセットをダウンロードします。例えば下の画像では、スペインのユーザがニューヨークにあるオリジンサーバへWebページをリクエストしますが、ページの静的アセットはイギリスのCDN「エッジ」サーバからロードすることで大西洋を横断するような時間のかかるHTTPリクエストを節約します。
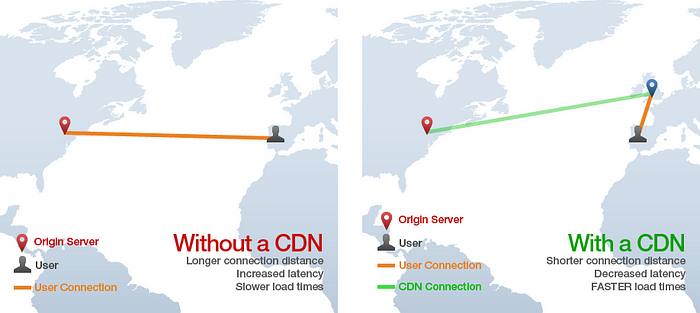
より詳細な紹介については、この記事を御覧ください。一般的に、Webアプリは常にCDNを使用してCSS、Javascript、画像、ビデオ、およびその他のアセットを提供する必要があります。一部のWebアプリでは、CDNを利用して静的なHTMLページを提供する場合もあります。
最後に
これがWebアーキテクチャ基礎の概要です。これがあなたのお役に立てば幸いです。来年か再来年には、これらのコンポーネントについて深く掘り下げた次の記事を投稿したいと思います。