2022/3 NoSQL Workbenchで始めるDynamoDB設計

本ブログサイトは、2019/5 Lightsailに移行しましたで紹介させていただいたようにMariaDBを利用していましたが、去年末にDynamoDBに移行しました。
RDBだと正規化させテーブルは役割ごとに分けますが、DynamoDBだと非正規化させ1つのテーブルに全てデータを入れ込むことが1つのベストプラクティスとされているようです。
移行するにあたり8テーブルを1テーブルに非正規化する上でNoSQL Workbenchに大変助けられましたので、今回はNoSQL Workbenchについて紹介します。
NoSQL Workbench
NoSQL WorkbenchはAWSが提供しているGUIツールです。
非正規化し1テーブルにしようとするとある意味整理されていない状態となり、カラムの抜け漏れ間違いがどこかにあるのでは?という感覚に陥ります。また、DynamoDB特有のGSI(グローバルセカンダリインデックス)を活用しようと設計すると1つのカラムに複数の意味を持たせるケースもあり、さらに混乱しました。
もちろんNoSQL Workbenchを使わなくても設計はできますが、使うことで
- 想定する利用データごとに仮データの投入ができ、視覚的に検証ができる
- DBを構築せずツール内で完結して検証ができる
- 設計終わったらDBを接続し、設定反映させることができる
というメリットがあり便利だと思いました。
Amazon DynamoDB
NoSQL Workbenchを起動した際の画面です。
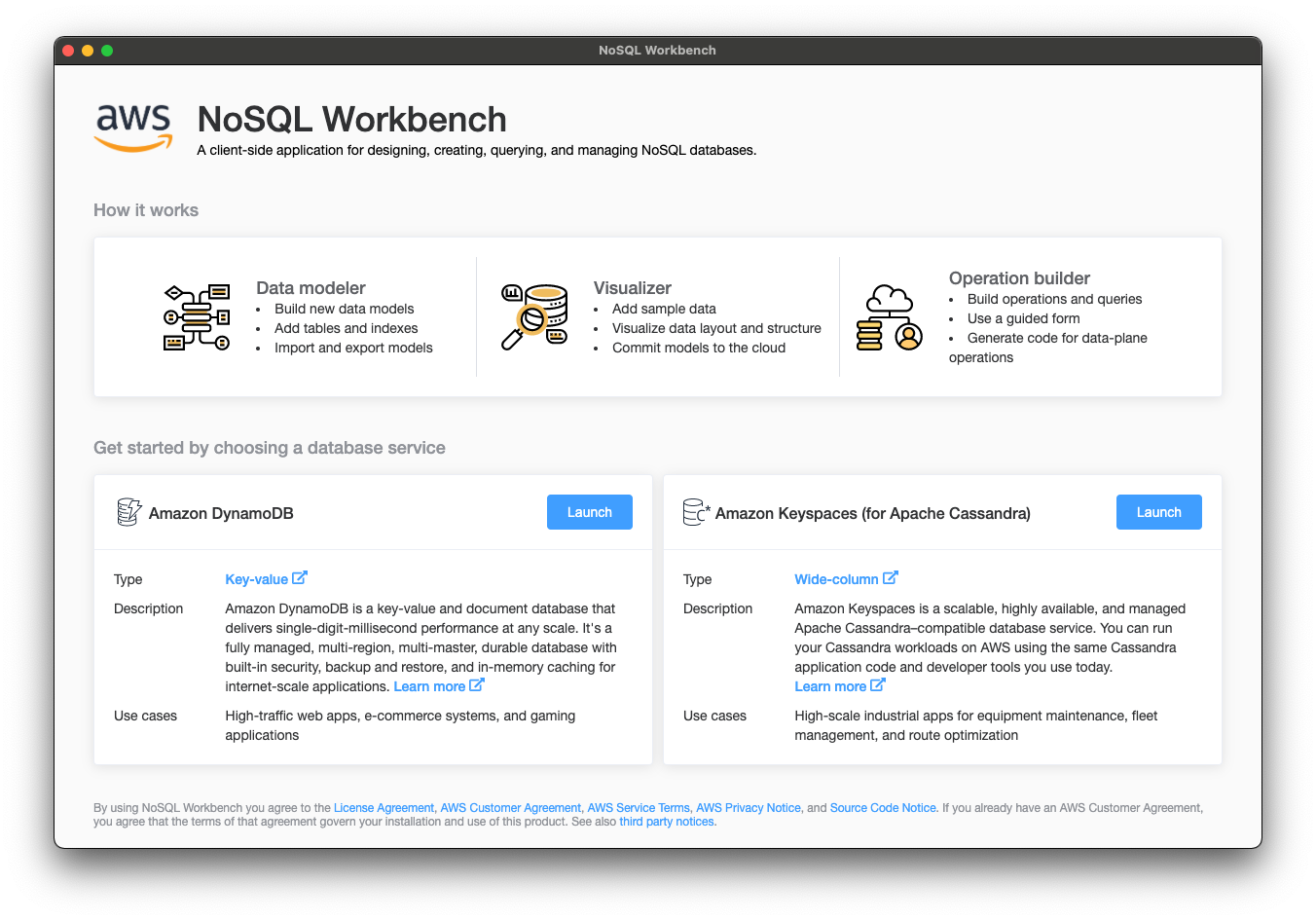
Amazon Keyspacesにも利用できるようですが、Amazon DynamoDBの「Launch」をクリックします。
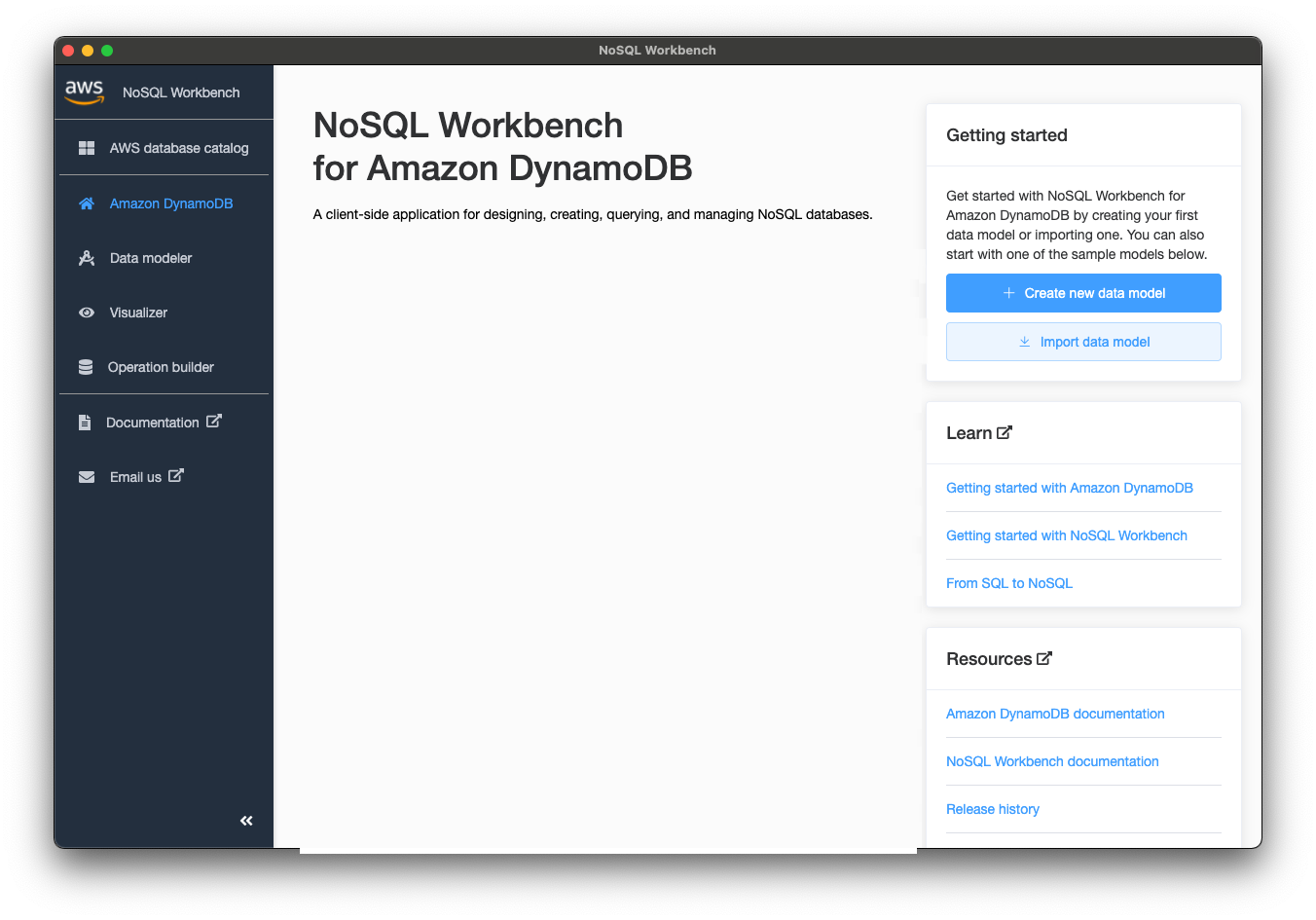
まずは、右側の「Create new data model」をクリックし、名前を入力します。 データモデルは、RDBでいうところのテーブルではなくデーターベースのような単位です。
Data modeler
データモデルを作成すると、Data modeler画面に遷移します。左側メニューも「Data modeler」になります。
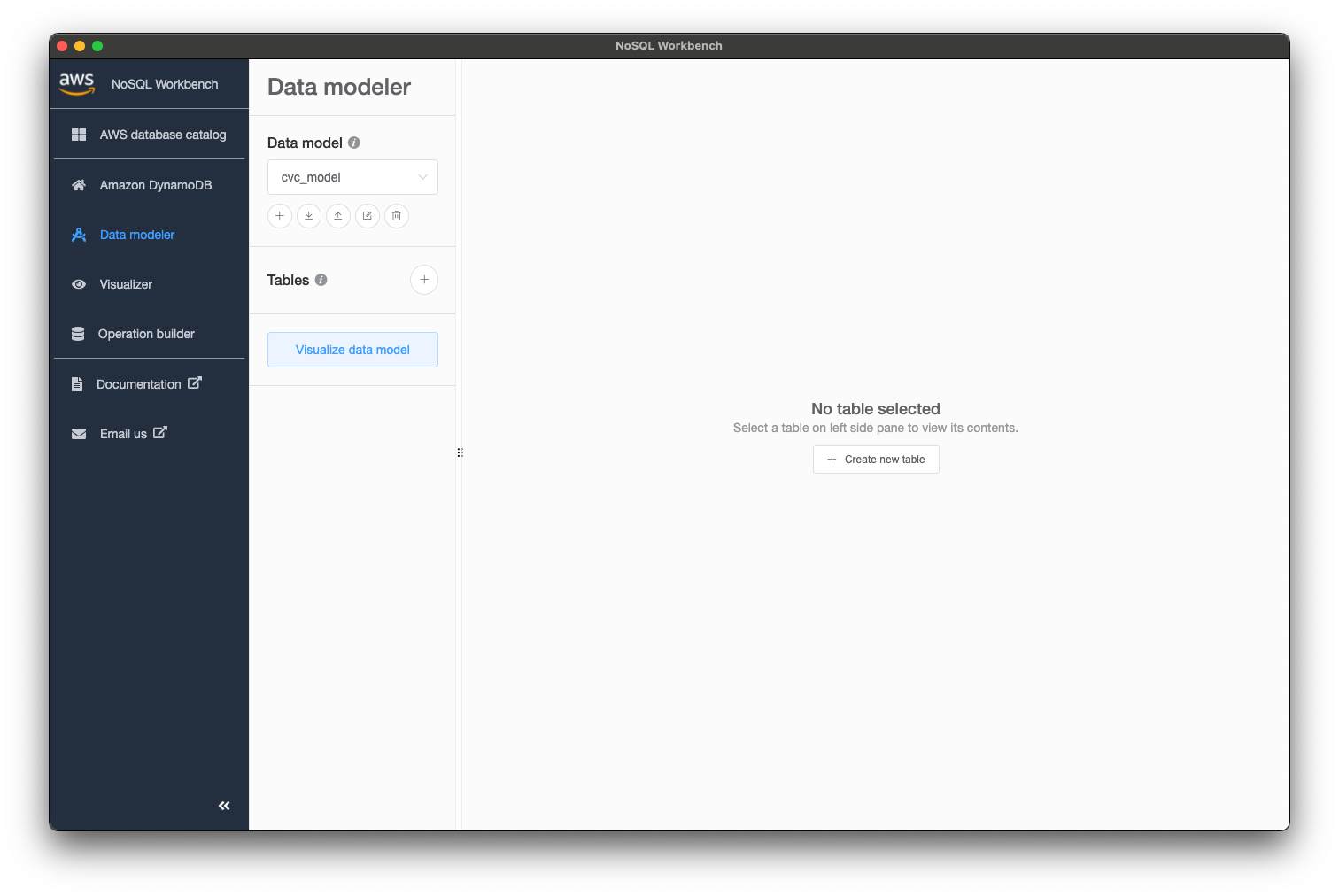
テーブル作成
今回はサンプルとして、部署テーブル(名称, 住所, 電話番号)、社員テーブル(名前, 入社日, 生年月日, 性別)を非正規化し、1テーブルで作成していきます。
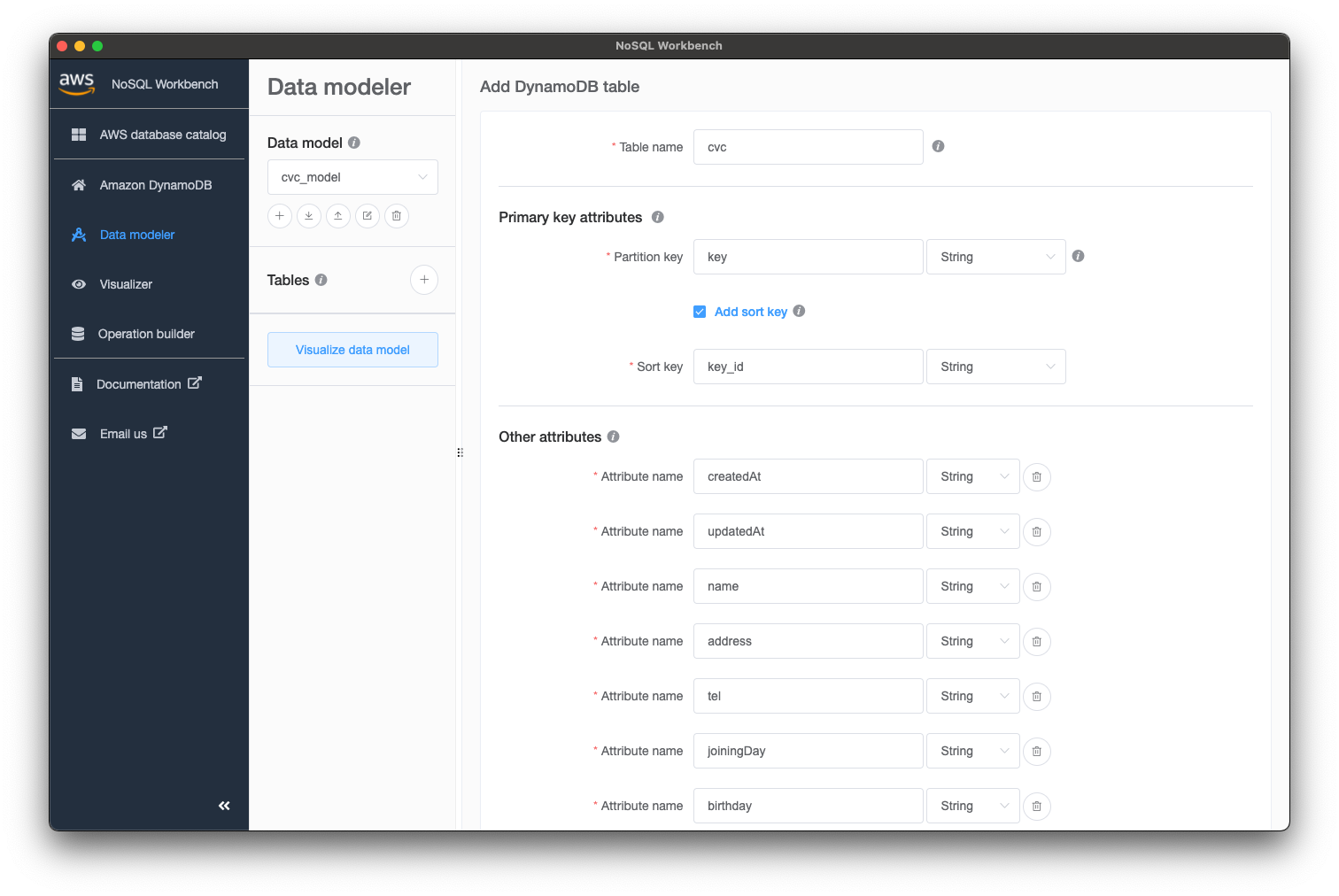
こういった感じでカラムを定義した後は、Facetを定義します。Facetはテストデータを投入しやすくするための仮想的な設定で、今回はdepartment(部署)、employee(社員)を定義しました。カラムとは違い実際のDynamoDBにはない設定項目です。
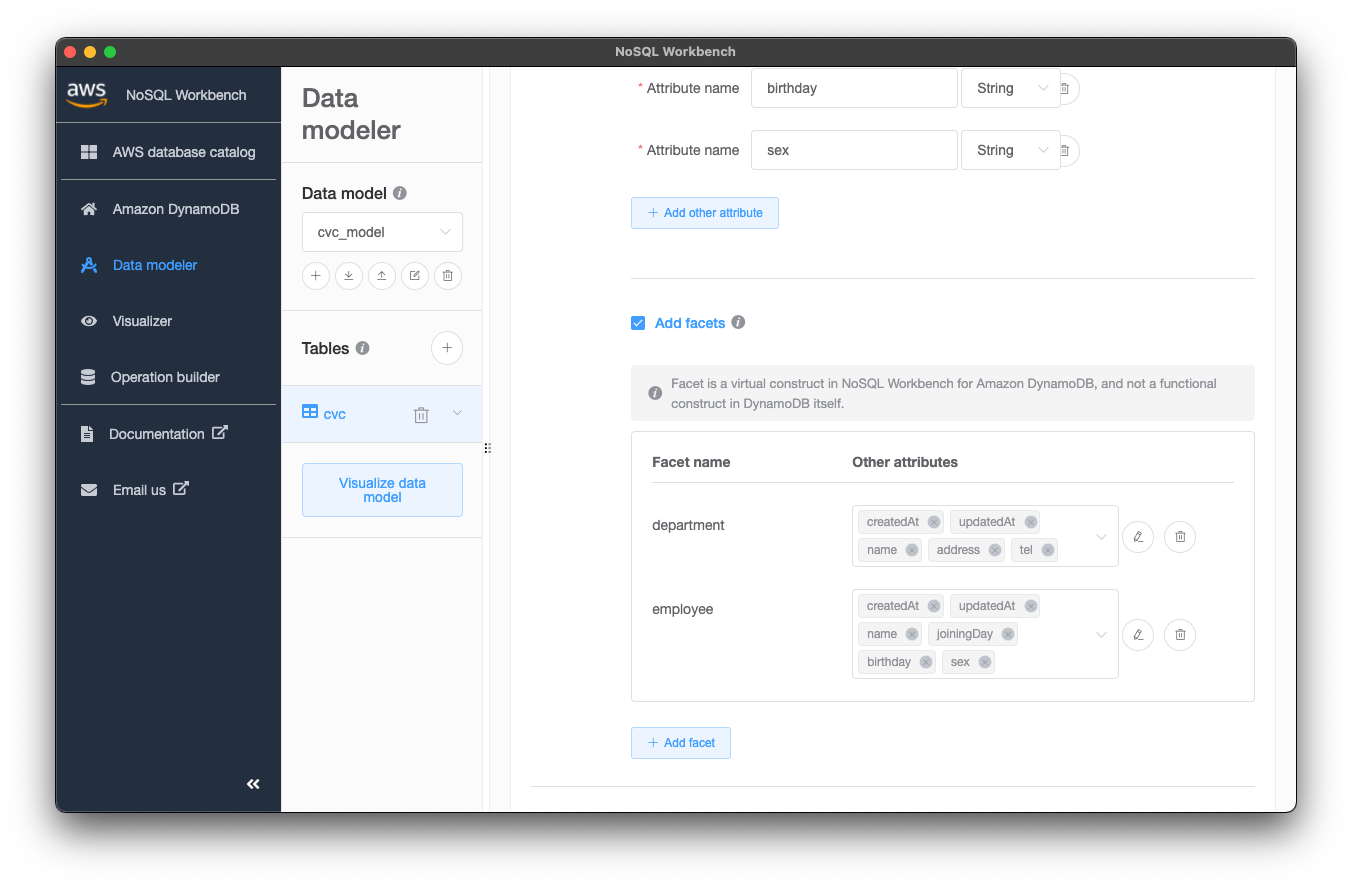
departmentとemployeeでは使いたいカラムが違うので設定しているOther attributesが違うことがわかると思います。このNoSQL Workbenchで一番便利だと感じたのは、このFacet設定でした。以降のVisualizer章で実感いただけると幸いです。
最後にGSIを設定します。GSIは独特ですがDynamoDBを活用する上で設計する上で大切な機能です。多くのブログでも紹介されている上、説明が長くなるためここでは省かせていただきます。
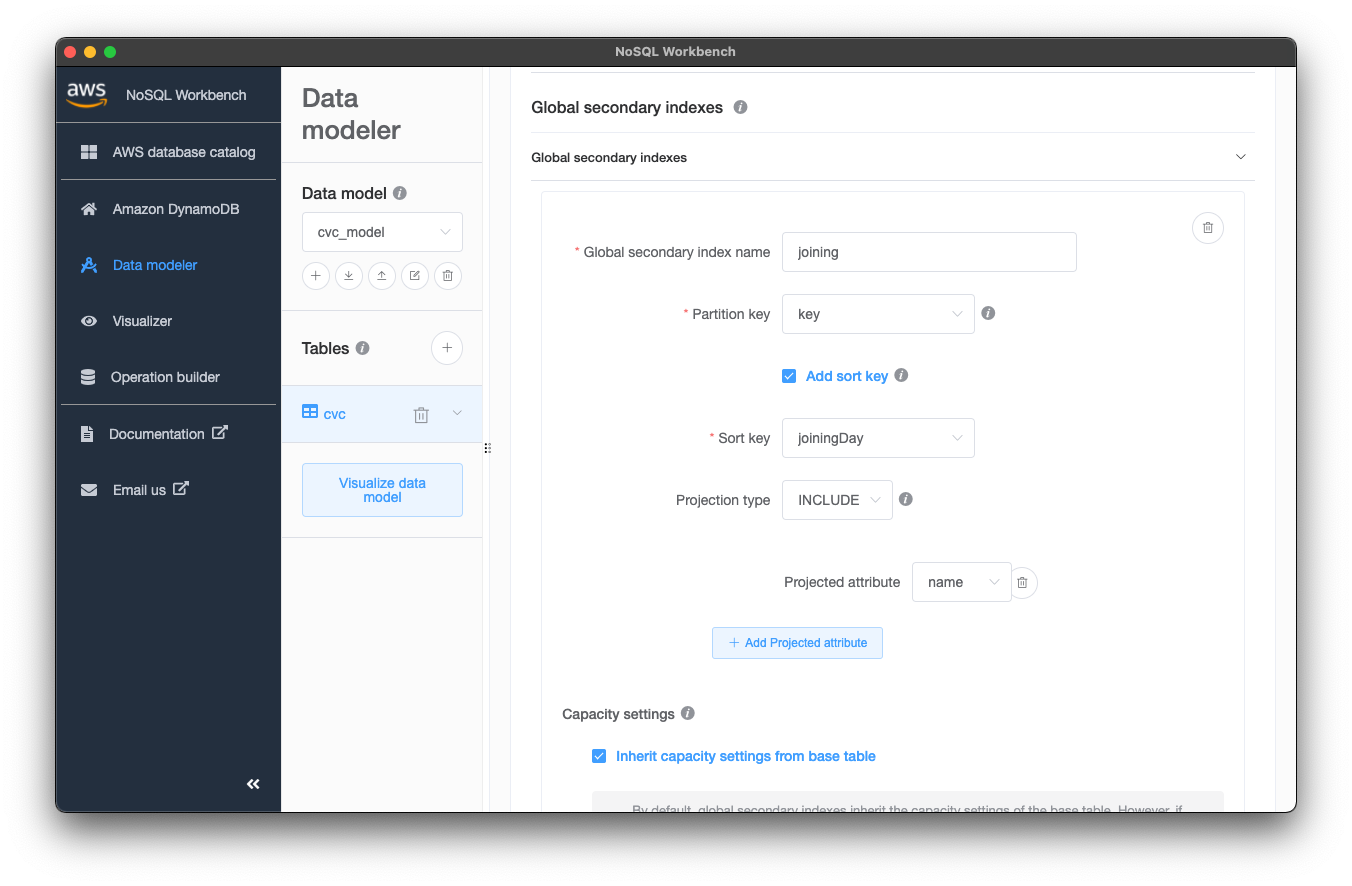
今回は社員情報を入社順に取得できるようにjoining GSIを定義しました。
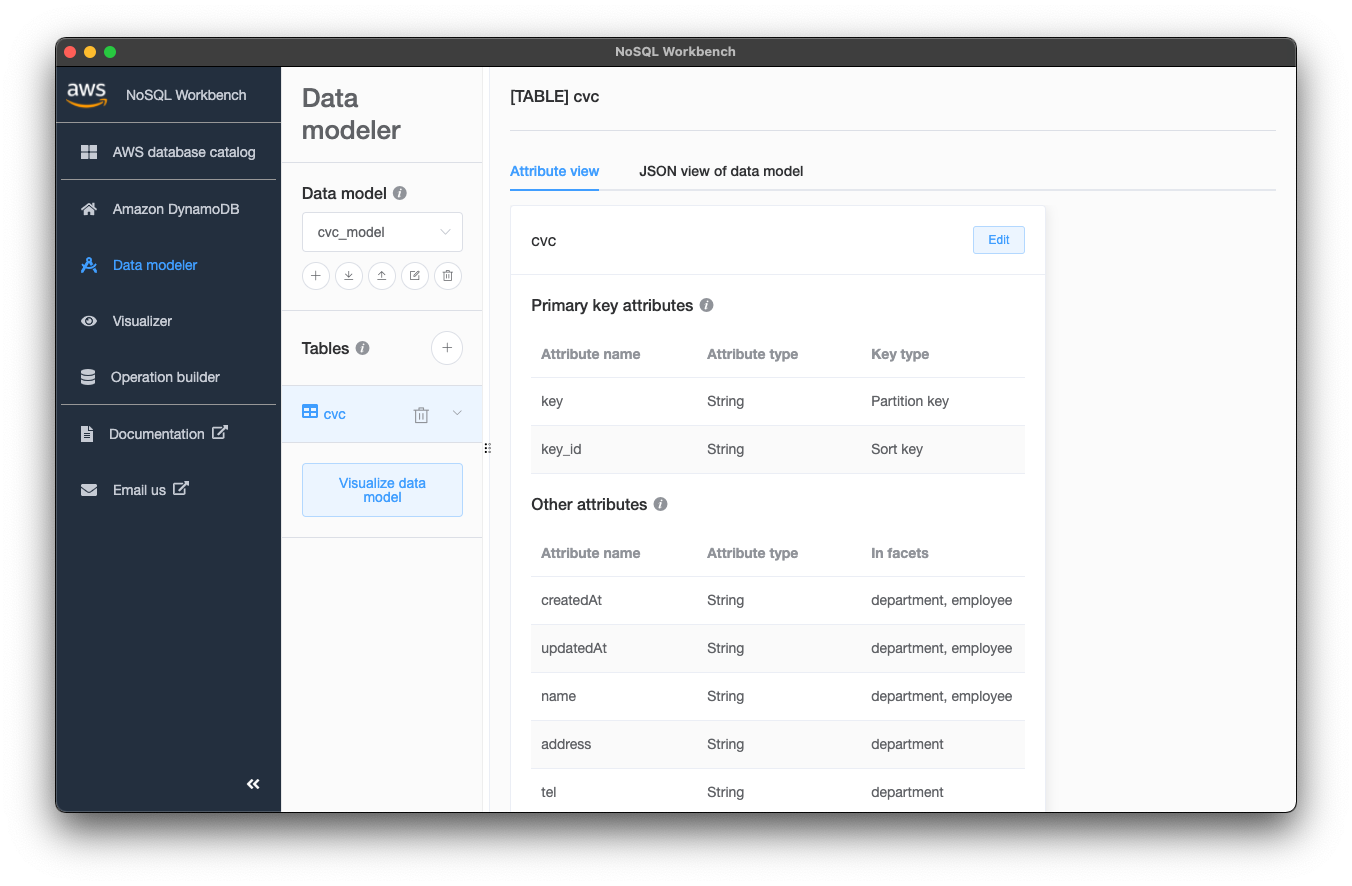
これで一通り定義し終わりましたので、テーブルを作成します。作成後は「Edit」から再度、カラム・Facet・GSIを変更・削除・追加できますので、気軽に一度作ってみてください。
Visualizer
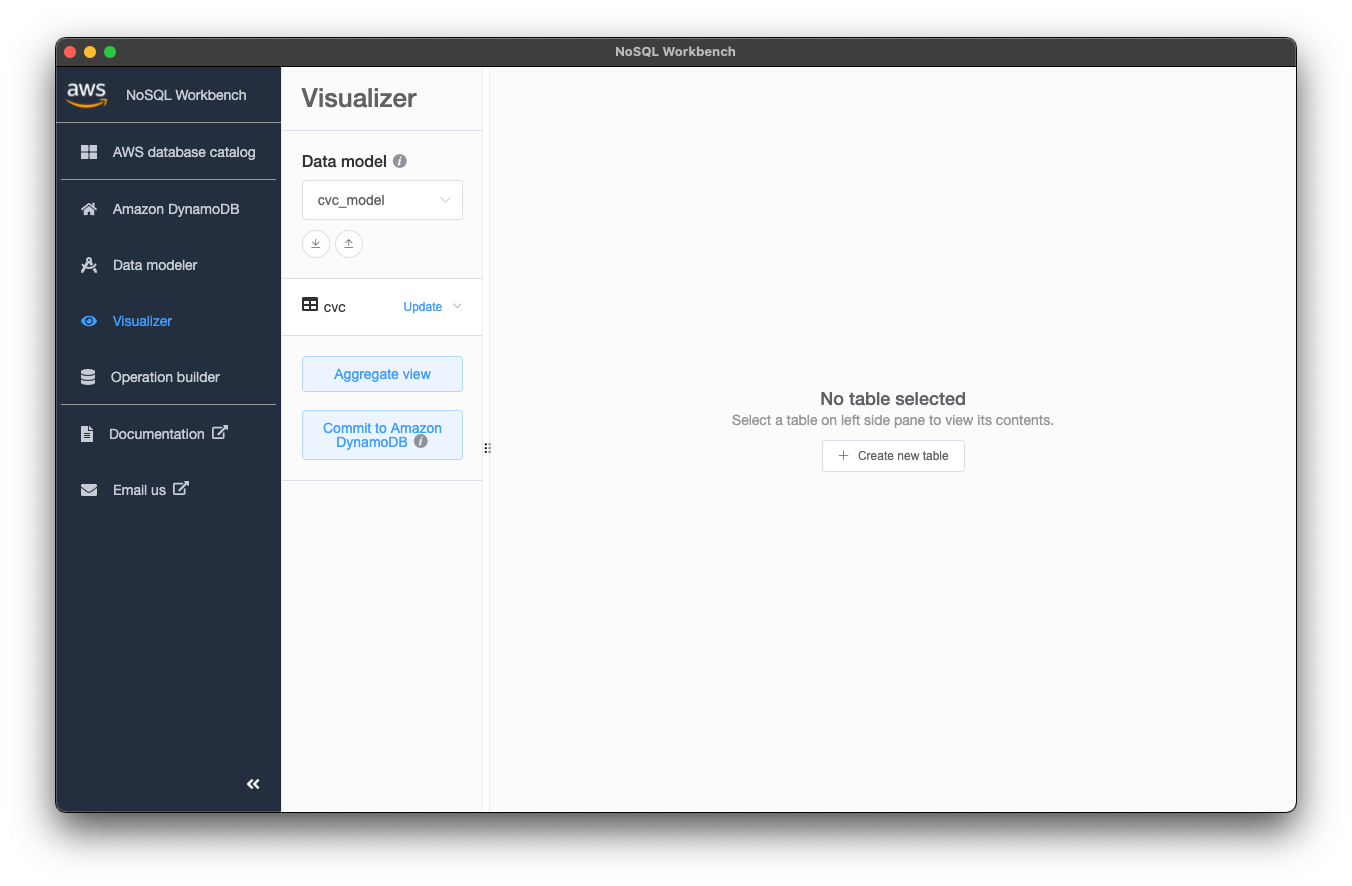
続いて左側メニュー「Visualizer」からVisualizer画面に遷移できます。Visualizerではデータの投入し意図通りのカラムとなっているか視覚的に確認ができます。
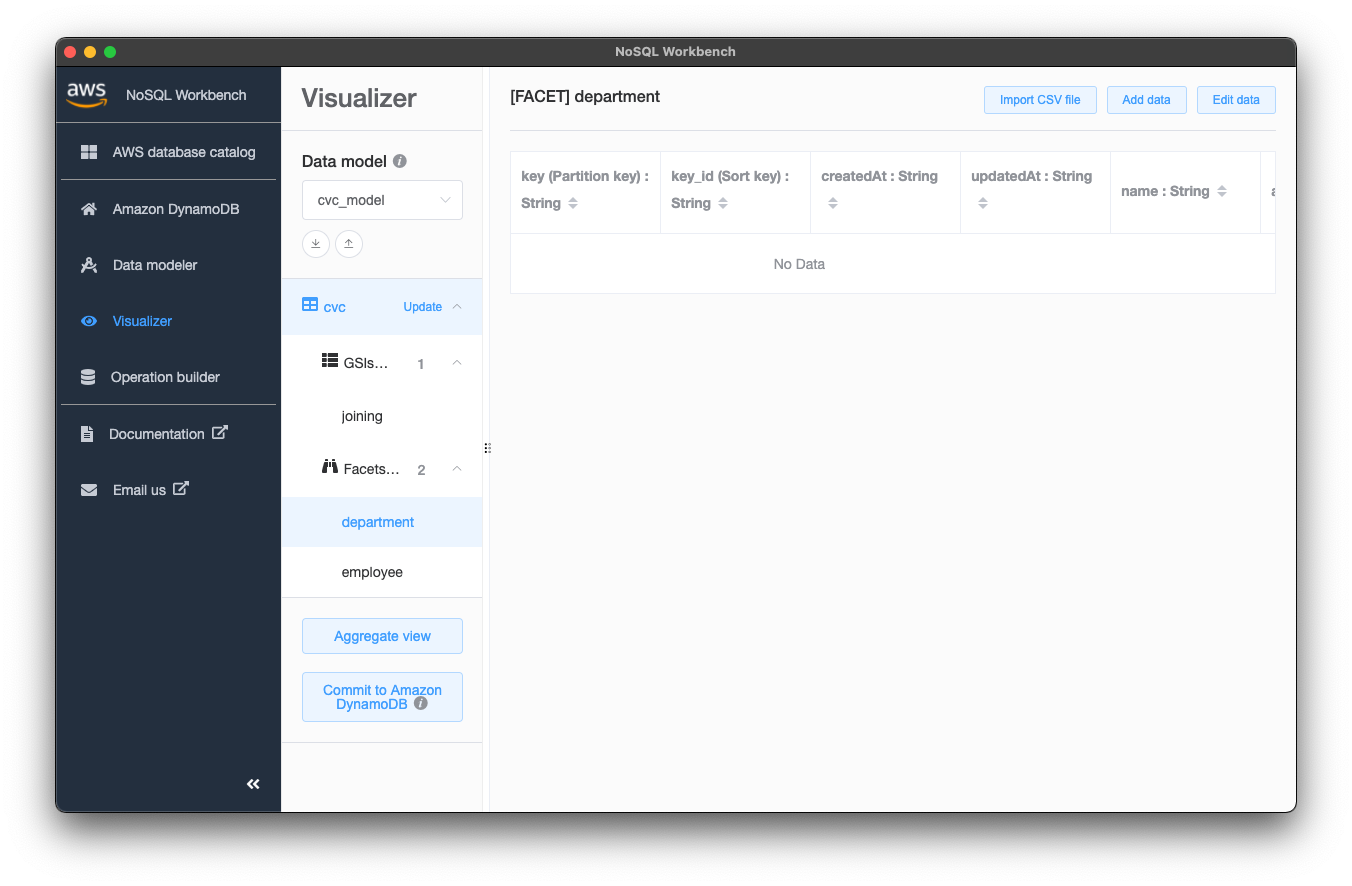
cvc_modelのちょっと下にあるcvcテーブル、Facets、departmentと順にクリックした後の画面がこちらです。 右上の「Add data」からデータを入力できます。
Facetのdepartmentとemployeeにデータを入力しました。以下の画像は、cvcテーブルをクリックした画面です。1つのテーブルに全てのデータが入っていることが実感できると思います。
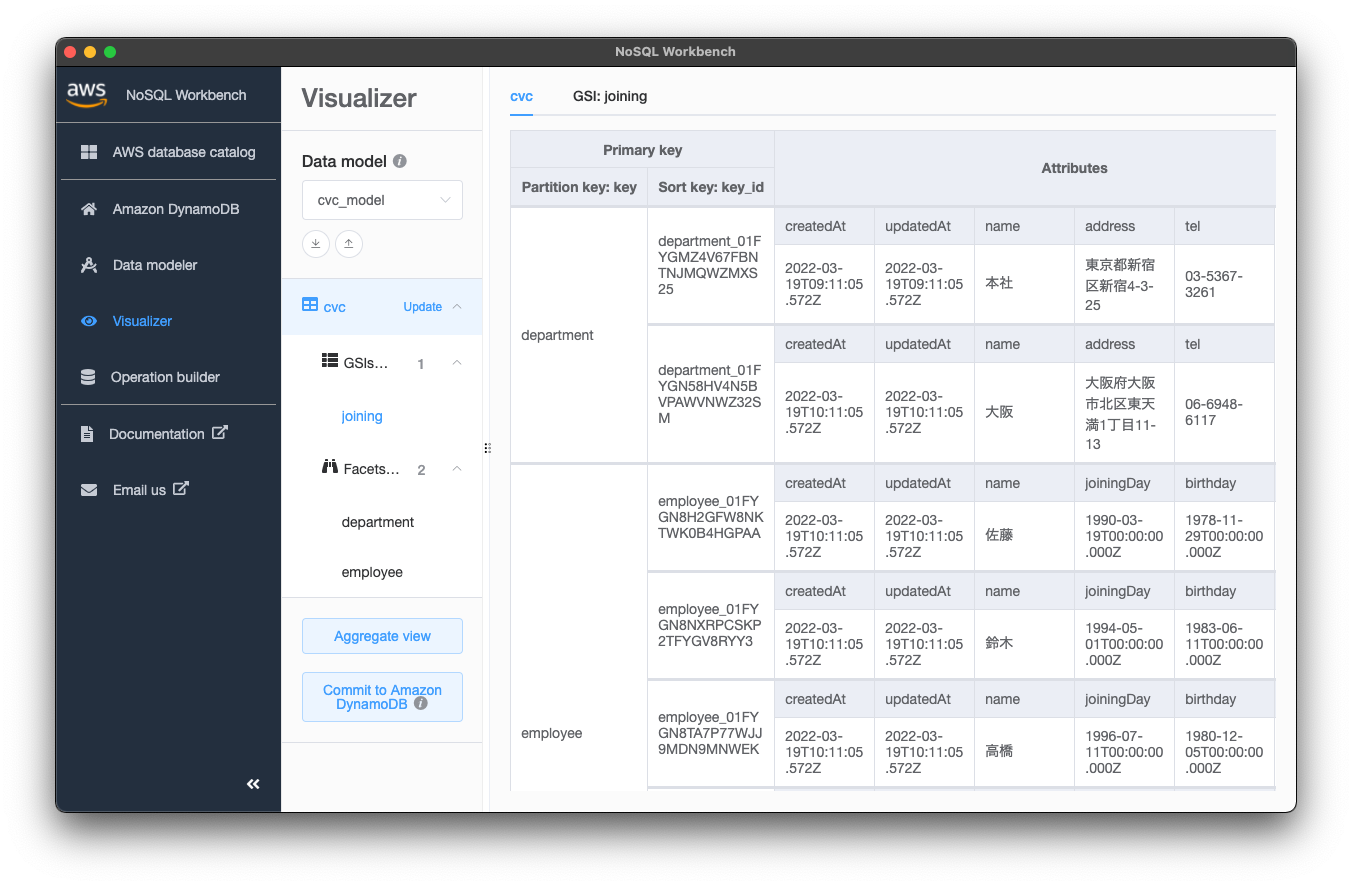
また、以下の画像のようにGSIも確認できます。今回テーブル作成時にjoning GSIの射影属性をnameだけに絞ったので、ここではname属性だけとなることも視覚的に確認できました。
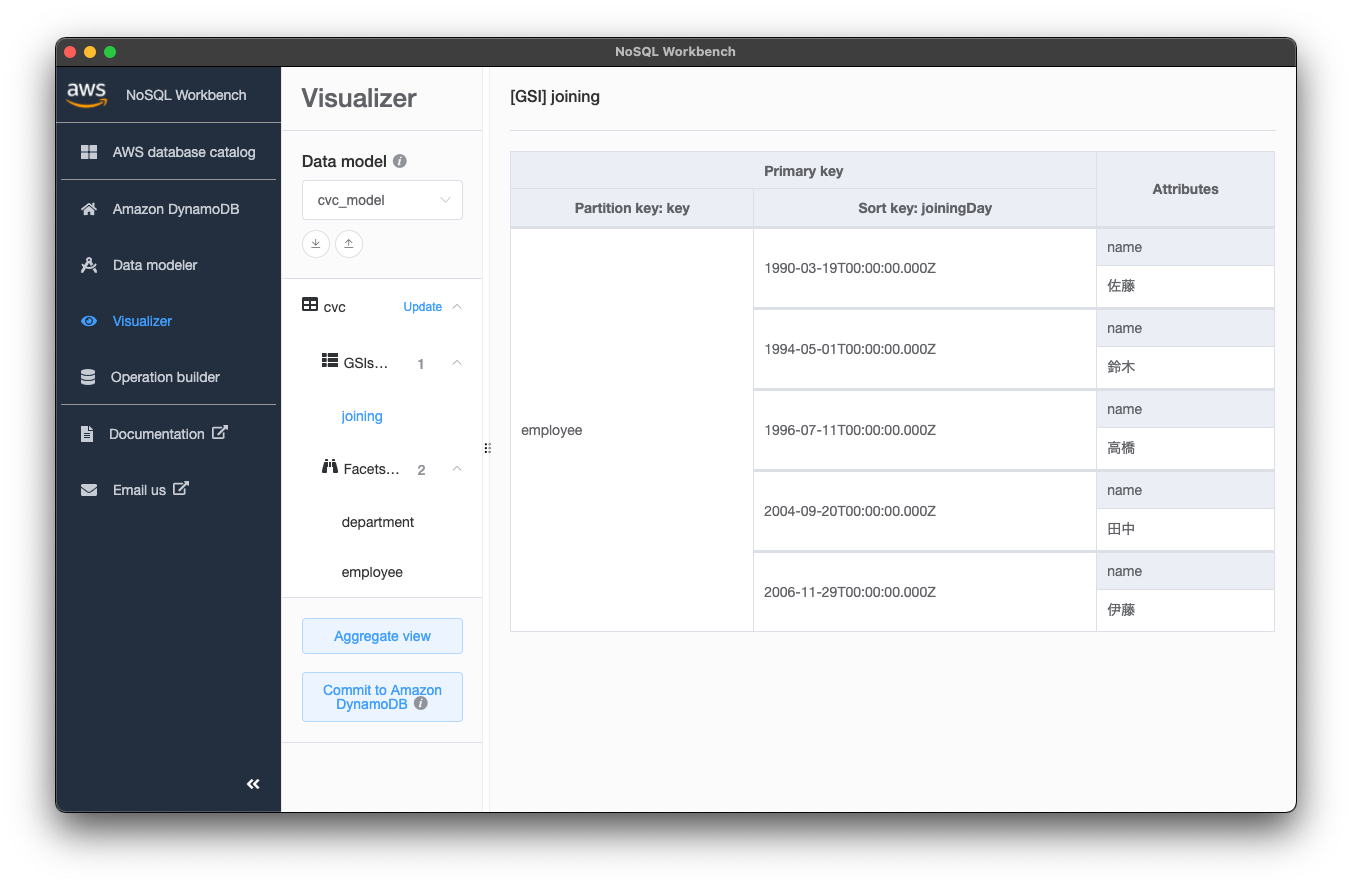
このVisualizerでデータを投入し、視覚的に確認しやすいことが少し伝わったかと思います。このようにデータを投入してみて足りないものがあれば、Data modelerに戻って設定を修正、Visualizerでデータ修正&確認していき、想定通りとなるまで検証を行いました。
Operation builder
最後に左側メニュー「Operation builder」からOperation builder画面に遷移します。
Operation builderでは開発用のローカルDynamoDBかAWS上のDynamoDBに、NoSQL Workbenchから接続できます。ローカルDynamoDBと接続するには構築&起動していることが前提となります。構築方法は、今回は省かせていただきます。
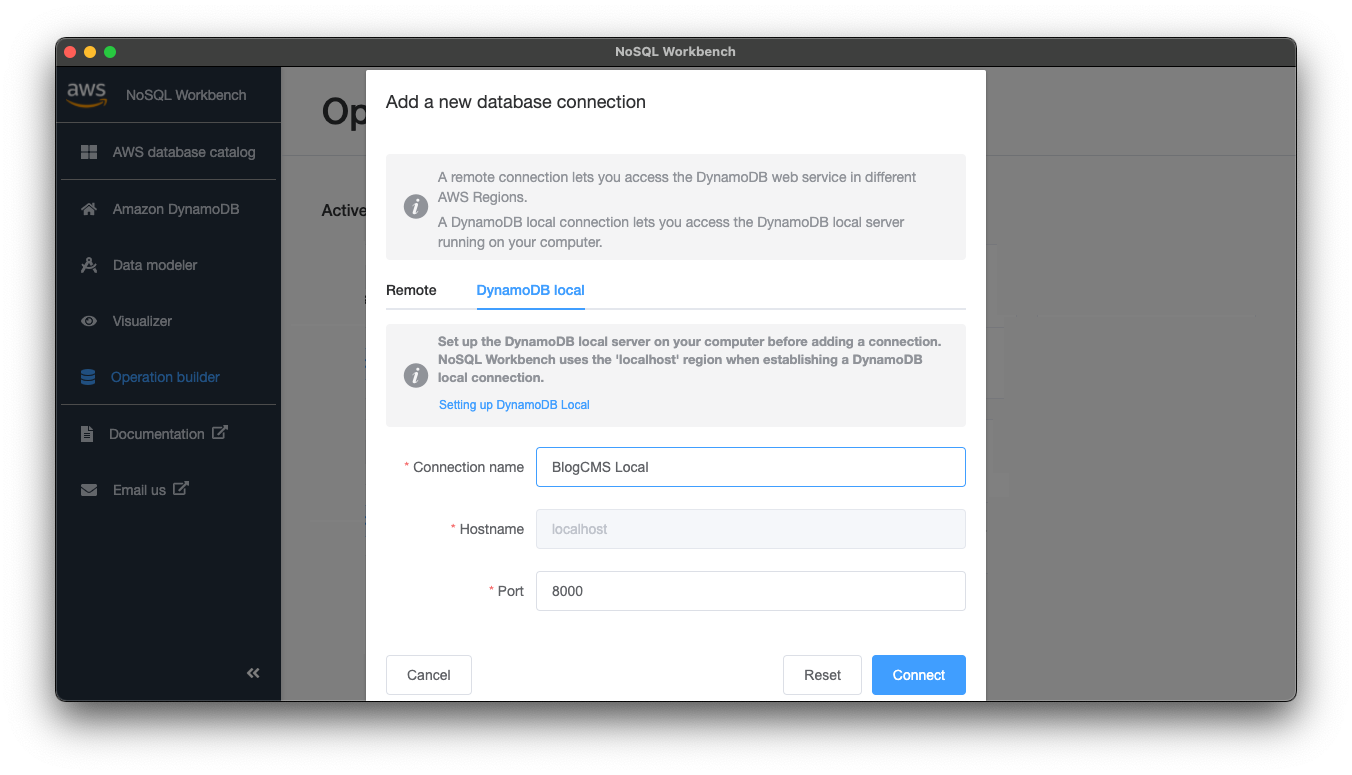
今回はローカルDynamoDBに接続します。「Add Connection」から接続設定として名前とローカルDynamoDBのポートを指定するだけで接続できます。
最後に、Visualizer画面の「Commit to Amazon DynamoDB」でデータをローカルDynamoDBに登録します。これで設計・検証したデータが登録されたので、アプリからローカルDynamoDBに接続し開発・実装を進めていけます。
終わりに
ありがたいことに弊社ブログのアクセス数は右肩上がりで、いずれ最低価格のlight sailでは捌き切れないことが見えていたのでDynamoDBに挑戦してみました。苦戦もしましたが結果的には、技術的にも運用的にもコスト的にも挑戦してよかったと思いました。
MariaDBを止めたことでメモリも400MBから200MB程度に減りました。また、DynamoDBアクセスすることでCPU負荷が上がるかと心配しましたが、逆にCPU使用率も下がりスパイクすることもなくなりました。
最後に、GSIやローカルDynamoDB構築方法など省かせていただいたので馴染みのない方には伝わりにくかったかもしれませんが、設計〜検証する上でNoSQL Workbenchが有用であることが伝わったかと思います。興味を持っていただけた方は、是非お試しください。